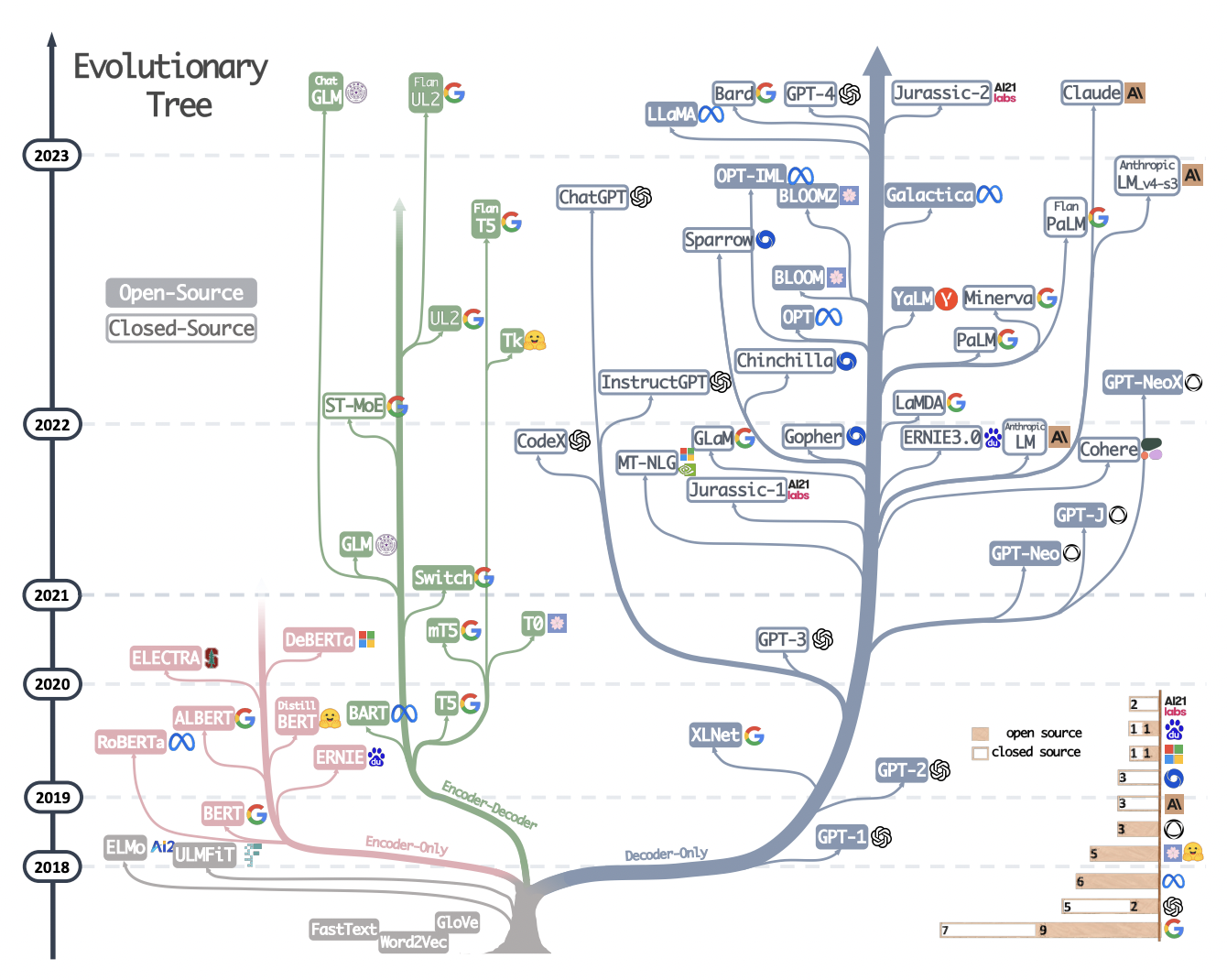
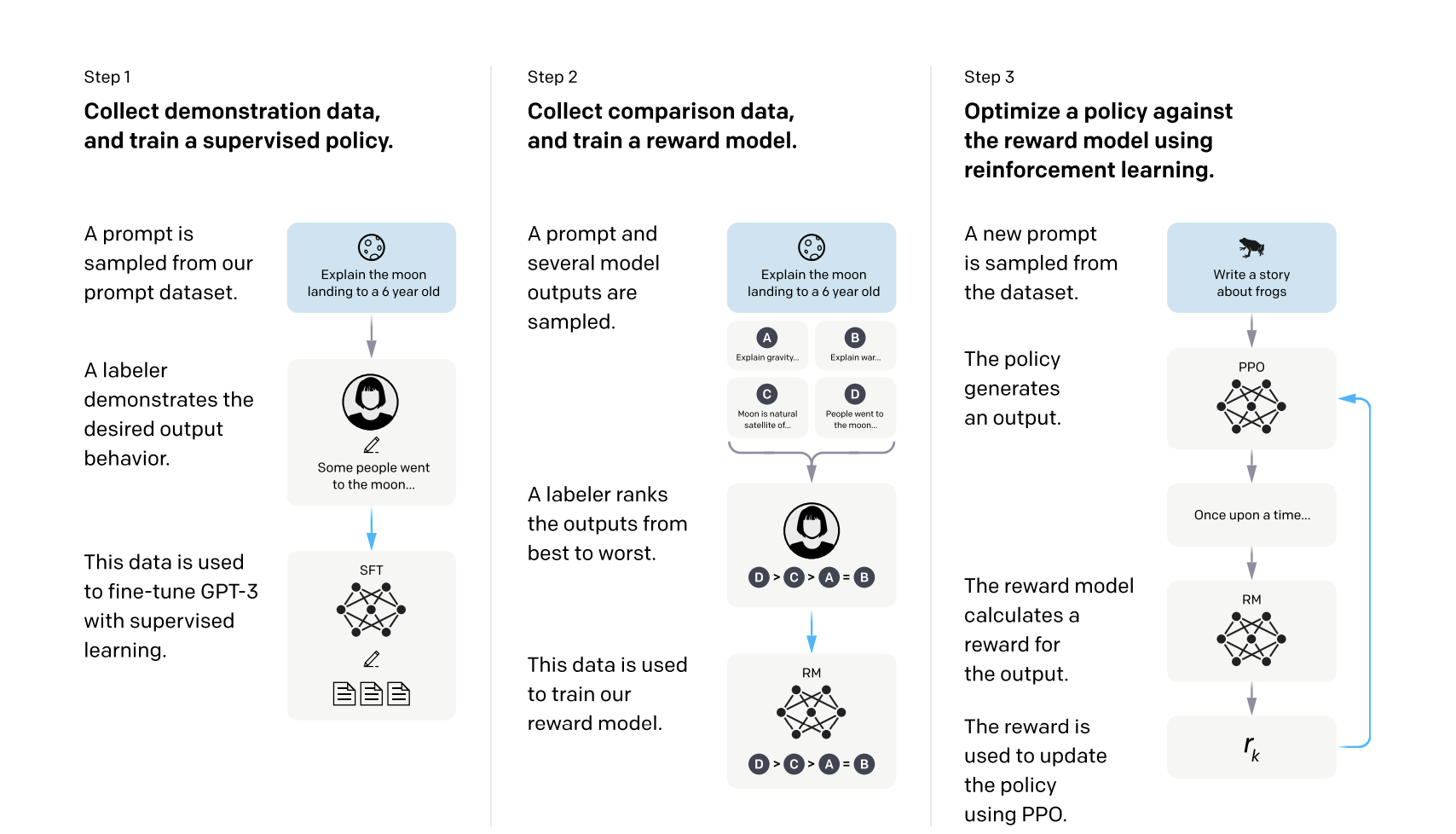
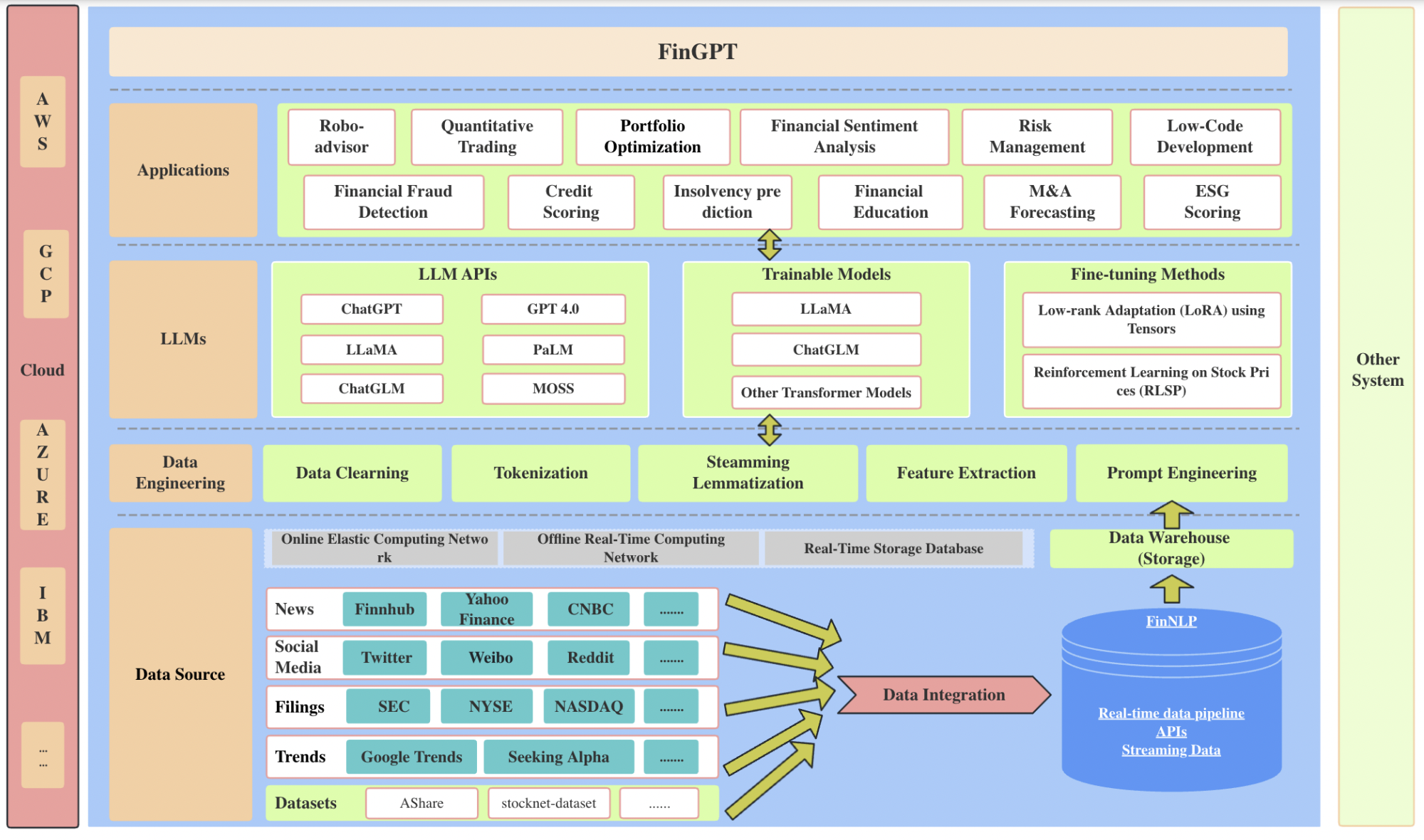
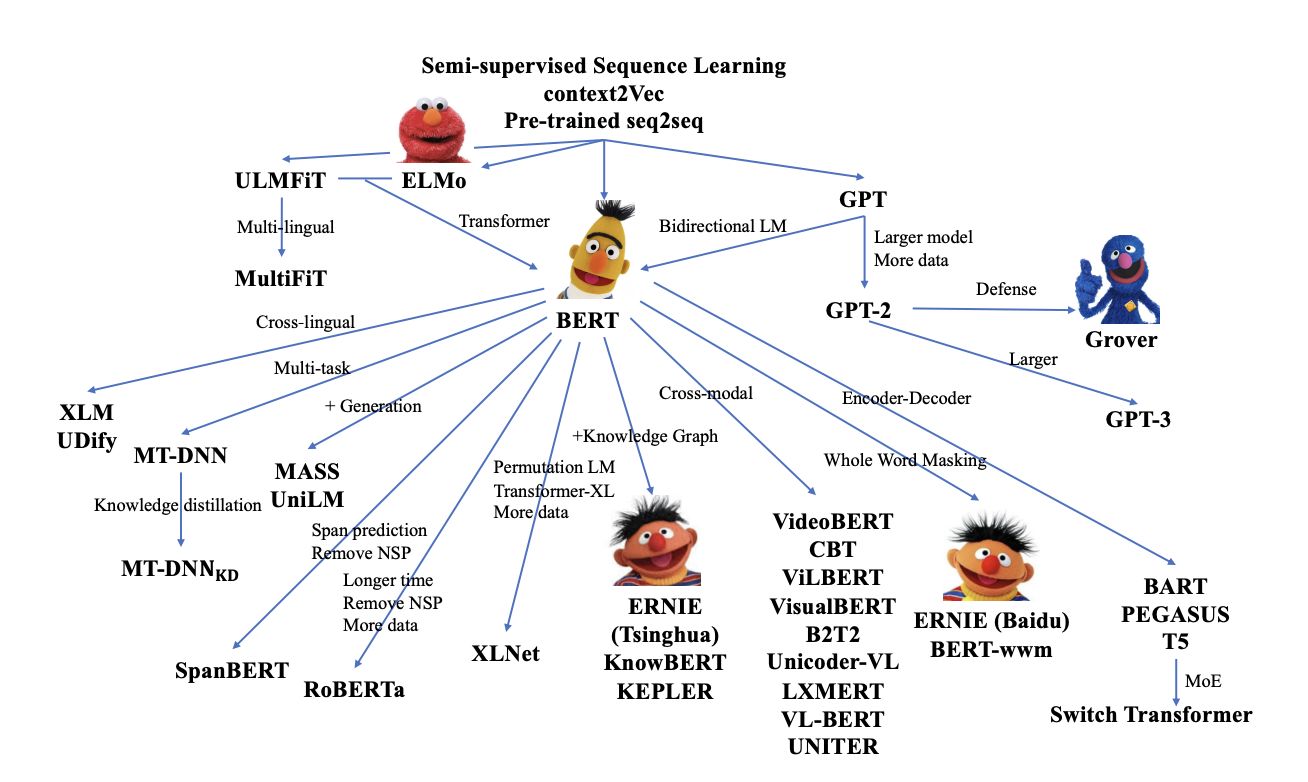
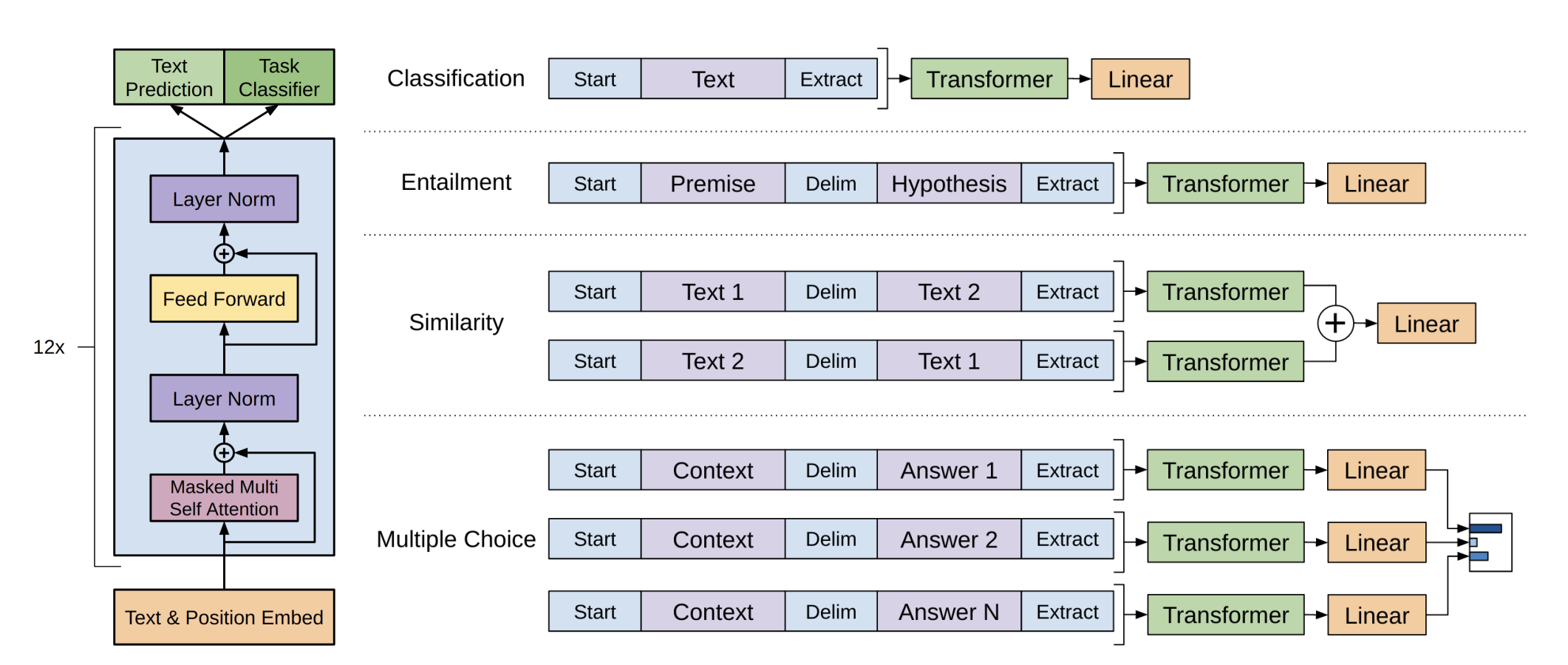
我们引入了 Codex,这是一种在 GitHub 上公开的代码上进行微调的 GPT 语言模型,并研究了它的 Python 代码编写能力。 Codex 的独特生产版本为 GitHub Copilot 提供支持。在我们发布的新评估集 HumanEval 上,用于衡量从文档字符串合成程序的功能正确性,我们的模型解决了 28.8% 的问题,而 GPT-3 解决了 0%,GPT-J 解决了 11.4%。此外,我们发现从模型中重复采样是一种令人惊讶的有效策略,可以为困难的提示提供可行的解决方案。使用这种方法,我们可以通过每个问题 100 个样本解决 70.2% 的问题。对我们的模型的仔细研究揭示了它的局限性,包括描述长操作链的文档字符串以及将操作绑定到变量的困难。最后,我们讨论部署强大的代码生成技术的潜在更广泛影响,涵盖安全性、安保性和经济性。